Resolviendo '1 billion row challenge' en Go en 3.8 segundos
Siempre me gustaron muchos los retos de programación donde hay que estrujarse el cerebro para entender el problema, saber de estructuras de datos y de cómo funcionan los ordenadores internamente.
Hace tiempo que no participaba en este tipo de competiciones, y la verdad estaba algo oxidado jeje. Es cierto que esto no es una competición, que ya existen muchas soliciones ya que "llego tarde" (se hizo algo viral hace tiempo).
El reto consiste en procesar un CSV de 14GB que contiene nombres de ciudades y la temperatura de medición. El objetivo es leerlo y procesarlo, agrupando las ciduades y sacando métricas de la media, máximo, mínimo, etc de las temperaturas siguiendo algunas reglas. Puedes ver toda la información en este enlace.
En mi caso me apetece resolverlo por diversión, para encontrar los cuellos de botella y resolverlos. Los procesos de optimización me encantan desde pequeño. Como tengo poco tiempo, no me voy a centrar en algunos detalles como repasar que los resultados sean correctos, etc. Mi objetivo es pasármelo bien, retomar mi antigua costumbre de resolver estos retos y ver hasta dónde puedo llegar en unas pocas horas que tengo libres.
He subido todo el código al siguiente repositorio (github.com/bypirob/1brc), por si quieres ver en profundidad la implementación.
La estructura del fichero de datos es como la siguiente:
Malaga;14.5
Almeria;4.6
Granada;-1.1
...
Para realizar pruebas he creado tres ficheros: small.txt que contiene 1000 líneas y puedo verificar el correcto funcionamiento, medium.txt que contiene 10 millones y puedo activar el profiler.
Primera solución
Siempre me gusta partir de una base sencilla, por lo que lo primero he hecho ha sido leer el fichero en Go línea por línea, y extraer los datos que necesito con funciones de la biblioteca estándar.
El código de la primera versión es el siguiente:
cities := make(map[string]*Station, 10000)
f, err := os.Open(os.Args[1])
check(err)
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
row := scanner.Text()
data := strings.Split(row, ";")
before, after := data[0], data[1]
temp, _ := strconv.ParseFloat(after, 64)
c := cities[before]
if c == nil {
cities[before] = &Station{
Sum: temp,
Count: 1,
}
} else {
c.Sum += temp
c.Count += 1
}
}
for k, v := range cities {
cities[k].Avg = v.Sum / v.Count
}
Vale, ya tengo una primera solución, vamos a ver cuanto tarda... 140 segundos o dos minutos y veinte segundos. Una eternidad en tiempo de CPUs.
En esta primera solución he utilizado una estructura para almacenar los datos del tipo `map[string]*Station. Uso un puntero para evitar realizar copias de datos en la estructura de la tabla hash, que posiblemente sea algo más lento.
Una herramienta muy útil en estos casos es el profiler para saber cómo se distribuye el tiempo en cada función el código:

El tema del profiler lo explicaré en otro post, así que suscríbete.
Segunda solución
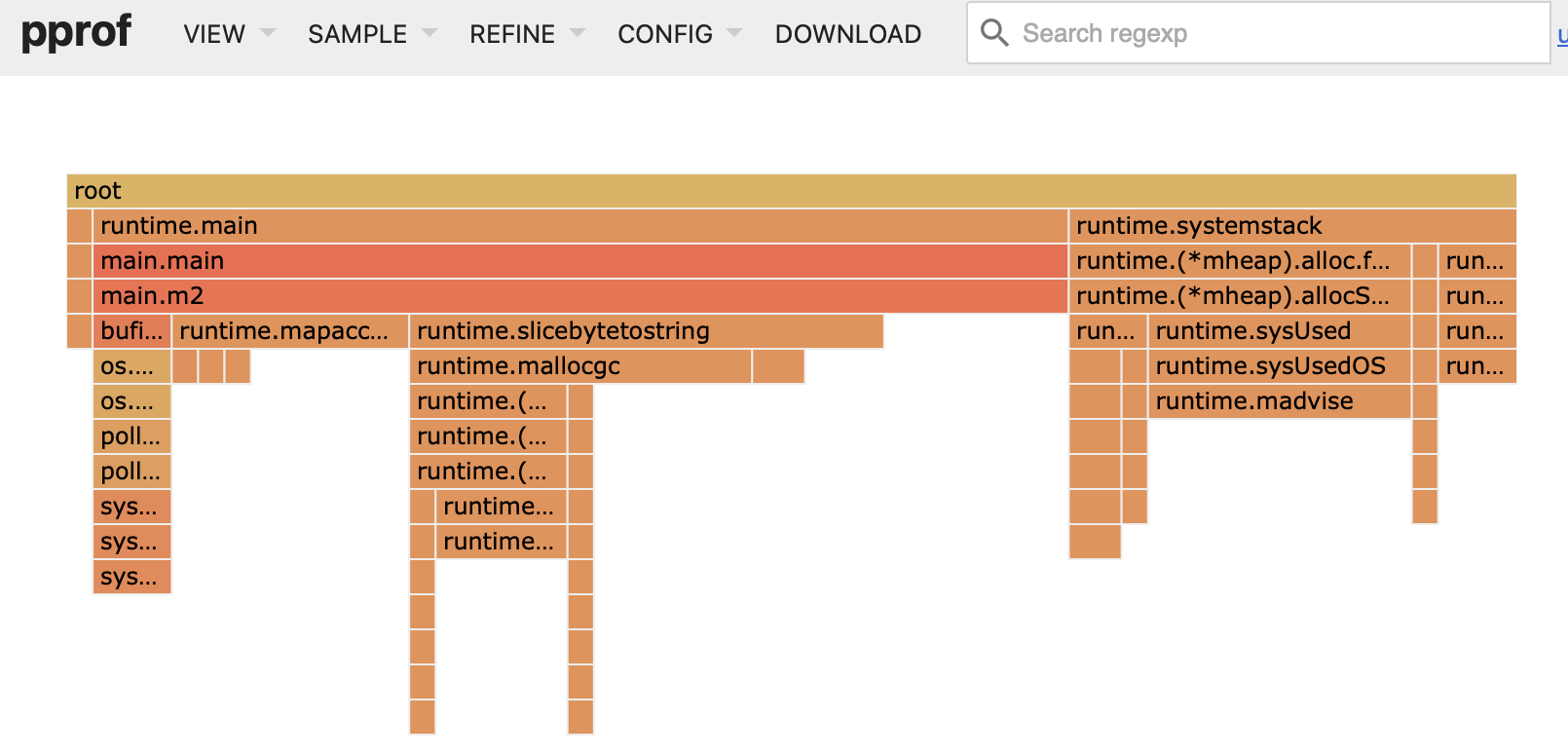
Si analizamos la foto anterior, vemos que principalmente el tiempo se va en la lectura del fichero y, en menor medida, lo siguiente más costoso es el procesamiento de las cadenas de texto. Lo explico por partes:
Lectura del fichero de 14GB
Puedes pensar que leer un fichero de 14GB es algo lento y que es el cuello de botella, y efectivamente lo es en esta solución pero no por limitaciones del hardware si no por una mala implementación.
En el ordenador desde el que escribo este post (un Macbook Pro M3 Pro), según leo en internet tiene una tasa de lectura de disco de 5GB por segundo. Por lo que debería poder leerlo en 3 segundos.
¿Dónde está el problema? En la implementación. El truco es leer chunks de un tamaño considerable en lugar de línea a línea. De esta forma, me traigo trozos del fichero de 8MB aproximadamente. De esta forma utilizamos menos el disco que es lo más costoso.
El primer problema aquí es que los chunks pueden dejar una línea inconsistente, ya que puede estar dividida en dos chunks. Esto es algo a lo que no he prestado atención ya que únicamente disponía de unas pocas horas y prefería centrarme en resolver el problema.
Procesamiento de cadenas de texto
El segundo problema que aunque oculto en la imagen, es que cuando haces split de una cadena generas varios arrays en memoria, uno para cada string en la que se divide la cadena inicial. Esto es inofensivo pero realizarlo 1.000.000.000 de veces añade complejidad, así que en esta solución comienzo a modificar la función que extrae los datos. Aún requiere de optimización, pero ya tengo yo el control.
La idea es simple, cuando te traes un chunk, recorro todos los caracteres y voy identificado el inicio y final de cada pieza de cada cadena mediante índices sobre el array de bytes. Aun así, hago un par de conversiones a string (que posteriormente eliminaremos).
Usar entero en lugar de flotante
Aquí me doy cuenta que los números son decimales con un único decimal, por lo que podemos representarlos con un entero y al final didivirlo por 10. Esto es algo más eficiente que trabajar con flotantes. Simplemente genero un string con el número conforme voy leyendo el chunk, saltándome el punto, y conviertiendo el array de bytes en string para pasarlo a la función Atoi (string -> int).
Tiempo de ejecución: 67s.
Tercera solución
En la imagen anterior, se ve cómo la solución anterior "pierde" tiempo realizando la conversión de byte array a string, así que en esta iteración las elimino. Te cuento cómo:
- Uno de los strings que se crean en cada iteración es el nombre de la ciudad, ya que por cada fila tienes que extraer el nombre que es su identificador. Aquí la clave es referenciar el array de bytes en el bufer que representa el nombre de la ciudad. Es decir
station = bufer[start:end]. - La otra conversión a string es el valor de la temperatura para poder pasarlo a la función Atoi (string -> int). Aquí encontré la función
unsafe.Stringque te permite utilizar un string para lectura sobre un array de bytes sin reservar nueva memoria (por eso lo de unsafe).
Tiempo de ejecución: 42s.

Cuarta solución
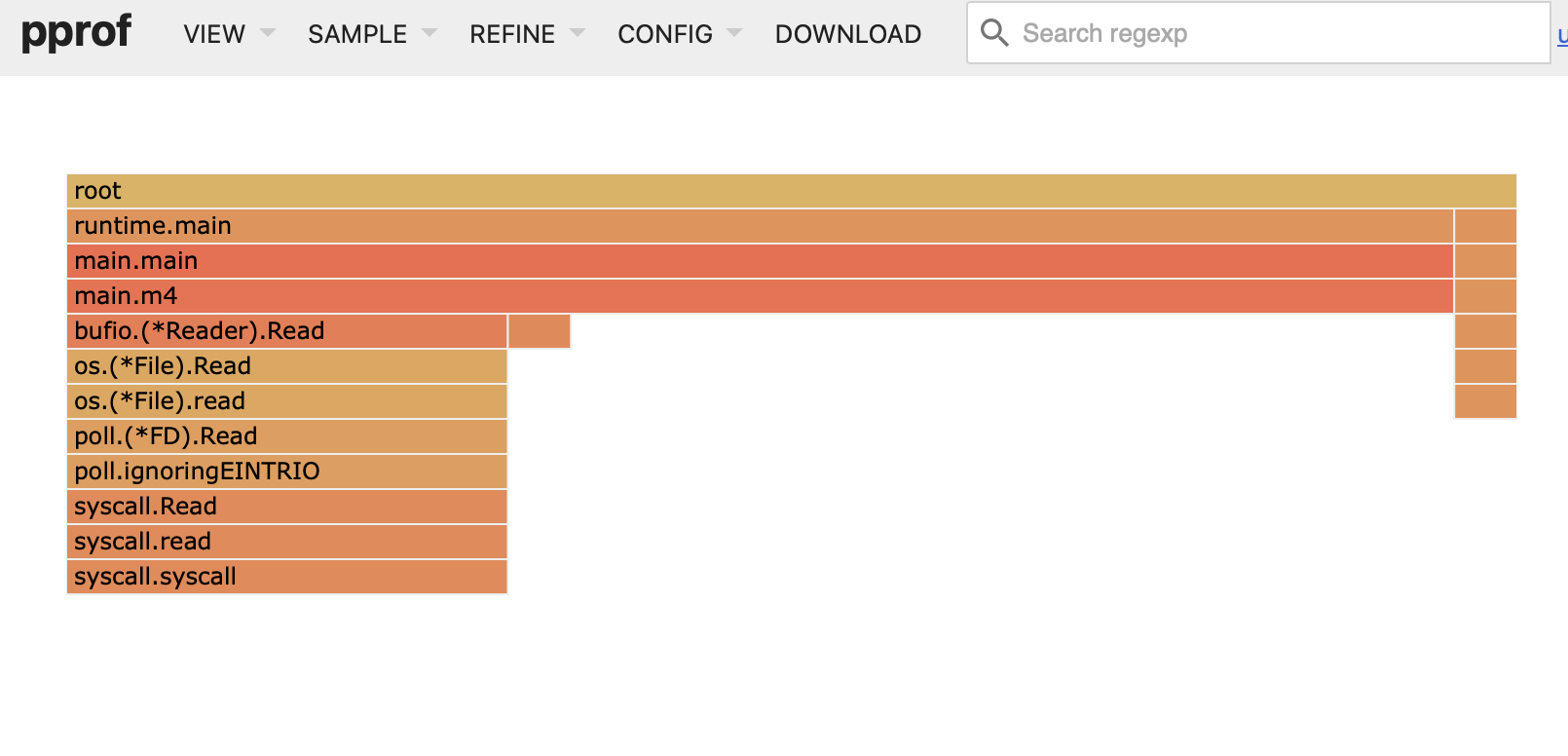
Analizando de nuevo el profiler, podemos ver cómo va cambiando la distribución de tiempos. Lo siguiente que más recursos consume (sin tener en cuenta la lectura) es acceder a la tabla hash (map[int]*Station) por lo que investignado la mejor forma es crear una tabla propia y calcular un hash con una función rápida y simple.
Al final crear una tabla hash "simplemente" es crear un array lo suficientemente grande, un algoritmo de hash rápido para acceder (leyendo sobre el tema encontré FNV-1), y gestión de colisiones mediante linear probing (básicamente mirar en las posiciones siguientes hasta que encuentres un hueco libre).
Además cuando calculas el hash, que es un entero, tienes que convertirlo al rango [0, hash_table_size), por lo que probablemente utilizarás el operador de módulo. Aquí estudiando la tabla hash, aprendí que si el tamaño es una potencia de 2, la operación de módulo equivale a una operación de máscara de bits menos 1. Es decir, si el tamaño de la tabla es 8 (3 bits) y tu hash es 15 puedes:
- 15 % 8 = 7
- 15 = 1111 => 1111 & (1000 - 1 = 0111) = 0111 = 7
Tiempo de ejecución: 28s.
Quinta solución
Ya el tiempo se ve claramente cómo se distribuye en lectura y procesamiento del chunk (además de la función Atoi, que al dejo para el final). Por tanto, ¿qué nos queda?
Paralelizar. Suena fácil pero requiere un rato de coordinar los hilos sin que haya bloqueos (como el problema de la cena de filósofos, que si estás empezando en esto te recomiendo resolverlo).
La idea es simple: tengo un hilo que se encarga de reducir y agregar el resultado de cada chunk en un array final, el hilo principal lee de disco los chunks, y por cada chunk crea un hilo (en realidad green threads ya que son goroutinas) que procesa el chunk, agrega los resultados (para evitar el coste de memoria de enviar cada línea) y los envía a un canal donde finalmente el reducer los termina de unificar.
Tiempo de ejecución: 5.2s.
Sexta solución
Lo último que me queda (aunque no lo último que se puede optimizar) es eliminar la función de conversión Atoi y extraer la temperatura directamente. Esto lo consigo con un entero (inicialmente 0) que voy sumando el dígito (byte(0,1,2,3,4,5,6,7,8,9) - byte('0')) y multiplico por 10. Finalmente multiplico por 1 o -1 según si la temperatura comienza por "-".
También en esta solución he corregido algunos errores que me he encontrado al redactar el post y repasar el código.
Con esto consigo mi reusltado final:
Tiempo de ejecución: 3.8 segundos 😎
Resultados
La verdad estoy contento ya que en unas pocas horas he sido capaz de pasar de 140s a 3.8s, entendiendo y aplicando conceptos que tenía en la cabeza algo oxidados y evitando el perfeccionimo de querer tener todos los datos correctos (algo que me encantaría realmente pero que no dispongo de más tiempo).
solucion
tiempo
solucion simple
140s
lectura en chunks, procesado de string, int vs float
67s
eliminar uso de strings
42s
custom hash map
28s
paralelizacion
5.2s
custom atoi y pequeños fixes
3.8s
Resolver este reto me ha permitido disfrutar bastante, refrescar conceptos de bajo nivel y me ha dado ganas de buscar algún otro pequeñs reto como este de vez en cuando.
Luego cuando veo una llamada web que tarda más de 1s me doy cuenta la cantidad de tiempo que se despercidia en CPUs, y por tanto, dinero. Esto lo dejo para un post de la categoría "reflexión".