Solving the '1 Billion Row Challenge' in Go in 3.8 seconds
I've always been fascinated by programming challenges that require you to rack your brain to understand the problem, know about data structures, and how computers work internally.
It had been a while since I participated in this type of competition, and I was admittedly a bit rusty haha. True, this isn't a competition, and many solutions already exist because I'm "late to the game" (it went somewhat viral a while ago).
The challenge is to process a 14GB CSV file containing city names and their recorded temperatures. The goal is to read and process it, grouping the cities and extracting metrics such as average, maximum, minimum, etc., of the temperatures following some rules. You can see all the information here.
In my case, I wanted to solve it for fun, to find and solve the bottlenecks. I've loved optimization processes since I was a child. Since I have limited time, I won't focus on certain details, such as reviewing that the results are correct, etc. My goal is to have fun, get back into the habit of solving these challenges, and see how far I can go in the few free hours I have.
I've uploaded all the code to the following repository (github.com/bypirob/1brc), in case you want to delve into the implementation.
The data file structure is as follows:
Malaga;14.5
Almeria;4.6
Granada;-1.1
...
For testing, I created three files: small.txt, which contains 1000 lines and allows me to verify correct operation, and medium.txt, which contains 10 million and lets me activate the profiler.
First Solution
I always like to start with a simple base, so the first thing I did was read the file in Go line by line, extracting the data I need using standard library functions.
The code for the first version is as follows:
cities := make(map[string]*Station, 10000)
f, err := os.Open(os.Args[1])
check(err)
defer f.Close()
scanner := bufio.NewScanner(f)
for scanner.Scan() {
row := scanner.Text()
data := strings.Split(row, ";")
before, after := data[0], data[1]
temp, _ := strconv.ParseFloat(after, 64)
c := cities[before]
if c == nil {
cities[before] = &Station{
Sum: temp,
Count: 1,
}
} else {
c.Sum += temp
c.Count += 1
}
}
for k, v := range cities {
cities[k].Avg = v.Sum / v.Count
}
Okay, I have a first solution, let's see how long it takes... 140 seconds or two minutes and twenty seconds. An eternity in CPU time.
In this first solution, I used a structure to store data of type
map[string]*Station. I use a pointer to avoid making copies of data in the hash table structure, which is probably a bit slower.
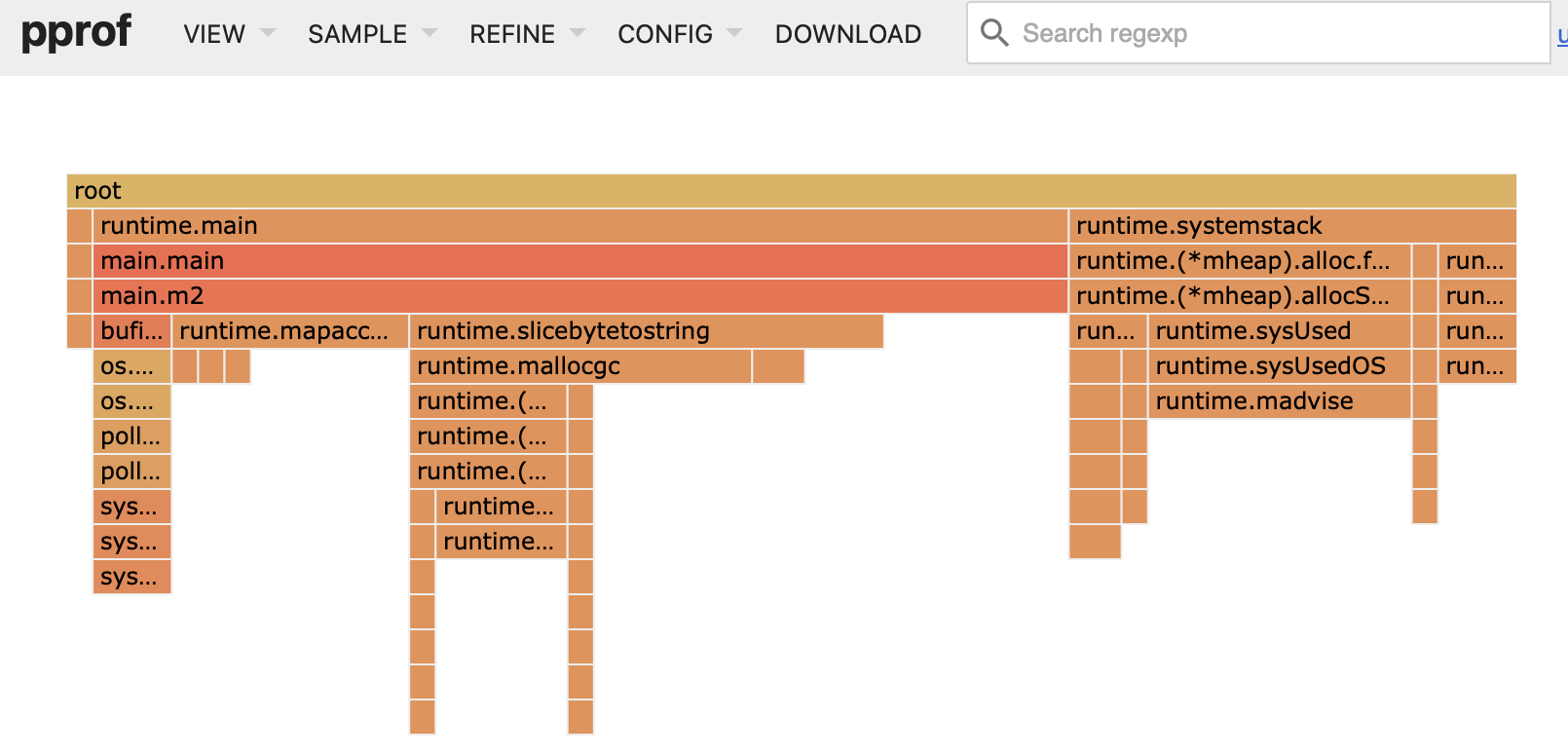
A very useful tool in these cases is the profiler to know how time is distributed in each function of the code:

I'll explain the profiler topic in another post, so subscribe.
Second Solution
If we analyze the previous picture, we see that most of the time is spent reading the file and, to a lesser extent, the next most costly thing is processing the text strings. I'll explain in parts:
Reading the 14GB File
You might think that reading a 14GB file is slow and that it's the bottleneck, and indeed it is in this solution but not because of hardware limitations but because of a poor implementation.
On the computer from which I write this post (a Macbook Pro M3 Pro), according to what I read on the internet, it has a disk read rate of 5GB per second. So, it should be able to read it in 3 seconds.
Where is the problem? In the implementation. The trick is to read chunks of a considerable size instead of line by line. This way, I bring in chunks of the file of approximately 8MB. This uses the disk less, which is the most costly part.
The first problem here is that the chunks can leave an inconsistent line since it may be divided between two chunks. This is something I have not paid attention to since I only had
a few hours and preferred to focus on solving the problem.
Text String Processing
The second problem, although hidden in the image, is that when you do a split of a string you generate several arrays in memory, one for each string into which the initial string is divided. This is harmless but doing it 1,000,000,000 times adds complexity, so in this solution I begin to modify the function that extracts the data. It still requires optimization, but I now have control.
The idea is simple, when you bring in a chunk, I go through all the characters and identify the start and end of each piece of each string by indexes on the byte array. Still, I do a couple of conversions to string (which we will later eliminate).
Using Integer Instead of Float
Here I realize that the numbers are decimals with only one decimal place, so we can represent them with an integer and at the end divide it by 10. This is more efficient than working with floats. I simply generate a string with the number as I read the chunk, skipping the dot, and converting the byte array to string to pass it to the Atoi function (string -> int).
Execution time: 67s.
Third Solution
In the previous image, you can see how the solution above "loses" time performing the conversion from byte array to string, so in this iteration I eliminate them. Here's how:
- One of the strings that are created in each iteration is the city name since for each row you have to extract the name which is its identifier. Here the key is to reference the byte array in the buffer that represents the city name. That is,
station = buffer[start:end]. - The other conversion to string is the value of the temperature to be able to pass it to the Atoi function (string -> int). Here I found the
unsafe.Stringfunction that allows you to use a string for reading on a byte array without allocating new memory (hence the unsafe).
Execution time: 42s.

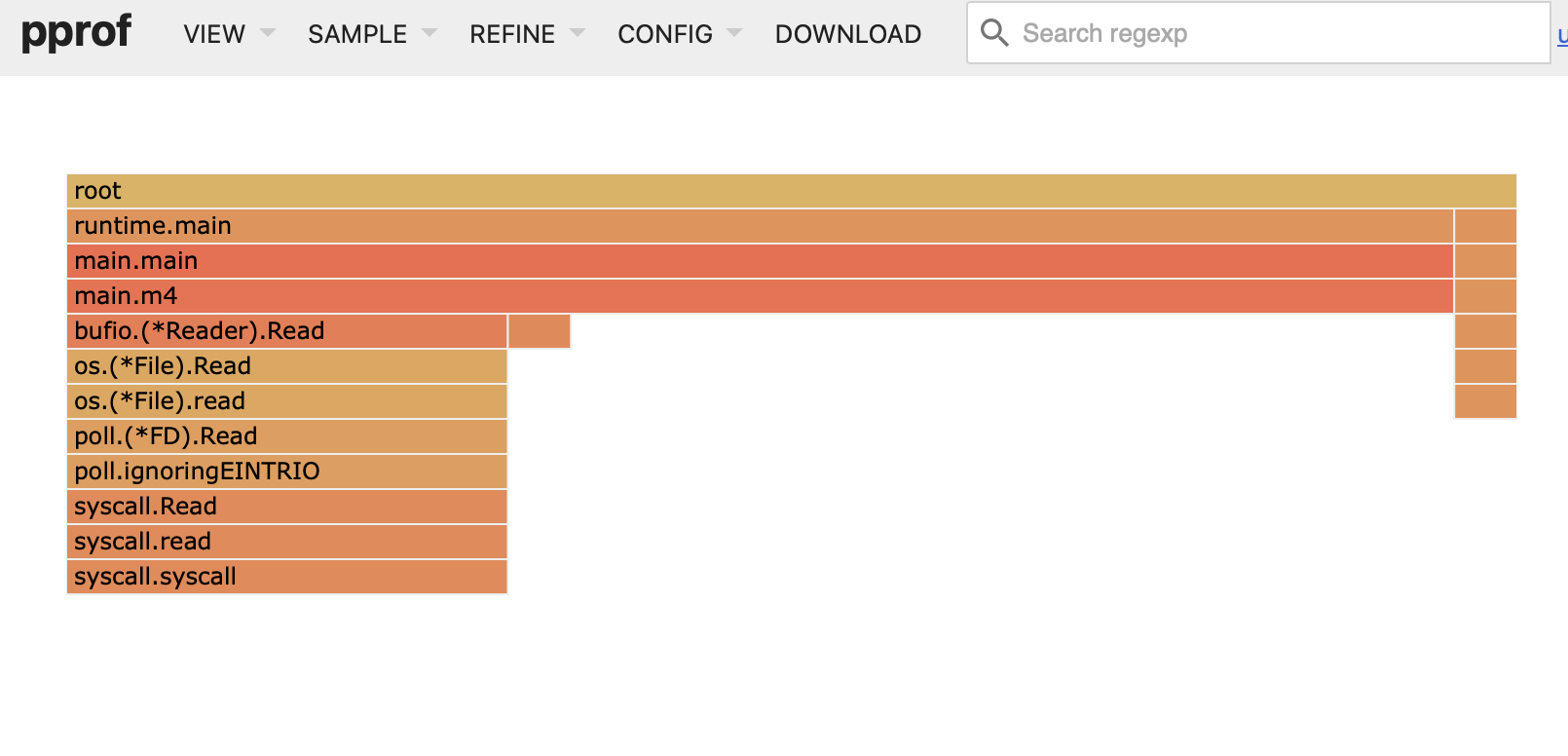
Fourth Solution
Analyzing the profiler again, we can see how the distribution of times changes. The next most resource-consuming thing (not considering reading) is accessing the hash table (map[int]*Station) so investigating the best way is to create a custom table and calculate a hash with a fast and simple function.
In the end, creating a hash table "simply" means creating an array large enough, a fast hash algorithm for access (reading about it I found FNV-1), and collision management through linear probing (basically looking at the following positions until you find a free spot).
Also, when you calculate the hash, which is an integer, you have to convert it to the range [0, hash_table_size), so you will probably use the modulo operator. Here, studying the hash table, I learned that if the size is a power of 2, the modulo operation is equivalent to a bit mask operation minus 1. That is, if the table size is 8 (3 bits) and your hash is 15 you can:
- 15 % 8 = 7
- 15 = 1111 => 1111 & (1000 - 1 = 0111) = 0111 = 7
Execution time: 28s.
Fifth Solution
Now the time is clearly distributed between reading and processing the chunk (in addition to the Atoi function, which I leave for the end). So, what's left?
Parallelizing. It sounds easy but requires some time to coordinate the threads without causing locks (like the dining philosophers problem, which if you're starting in this I recommend solving).
The idea is simple: have a thread that is in charge of reducing and aggregating the result of each chunk into a final array, the main thread reads the disk chunks, and for each chunk creates a thread (actually green threads since they are goroutines) that processes the chunk, aggregates the results (to avoid the memory cost of sending each line) and sends them to a channel where the reducer finally unifies them.
Execution time: 5.2s.
Sixth Solution
The last thing left (though not the last thing that can be optimized) is to eliminate the Atoi conversion function and directly extract the temperature. I achieve this with an integer (initially 0) that I sum up the digit (byte(0,1,2,3,4,5,6,7,8,9) - byte('0')) and multiply by 10. Finally, I multiply by 1 or -1 depending on whether the temperature starts
with "-".
Also in this solution, I corrected some errors I found while writing the post and reviewing the code.
With this, I achieve my final result:
Execution time: 3.8 seconds 😎
Results
Honestly, I'm pleased because in just a few hours I was able to go from 140s to 3.8s, understanding and applying concepts that I had a bit rusty in my mind and avoiding perfectionism in wanting to have all the data correct (something I would really love but don't have more time for).
Solution
Time
Simple solution
140s
Reading in chunks, string processing, int vs float
67s
Eliminating use of strings
42s
Custom hash map
28s
Parallelization
5.2s
Custom atoi and minor fixes
3.8s
Solving this challenge has allowed me to enjoy a lot, refresh low-level concepts, and has made me want to look for another small challenge like this from time to time.
Then, when I see a web call that takes more than 1s, I realize the amount of time that is wasted on CPUs, and therefore, money. I'll leave this for a post in the "reflection" category.