
Llevo los últimos meses trabajando con Clickhouse y, ha sido todo un reto muy interesante tanto el aprender los conceptos para poder trabajar de forma óptima con los datos, como para poder desplegar y escalar un cluster en producción. También hay errores y problemas con los metadatos y la coordinación de zookeeper, migración a clickhouse-keeper, gestión del almacenamiento en AWS, backups, actualizaciones...
Qué es Clickhouse
Clickhouse es una base de datos analítica muy interesante, open source y muy eficiente. Este tipo de bases de datos se conoce como OLAP o OnLine Analytical Processing. A diferencia de los sistemas OLTP o OnLine Transaction Processing que están pensados y optimizados para trabajar con operaciones individuales frecuentes como insert/delete/update de filas, como MySQL o PostgreSQL, las bases de datos analíticas como Clickhouse están diseñadas para procesar, tanto en lectura como en escritura, grandes volúmenes de datos.
MergeTree
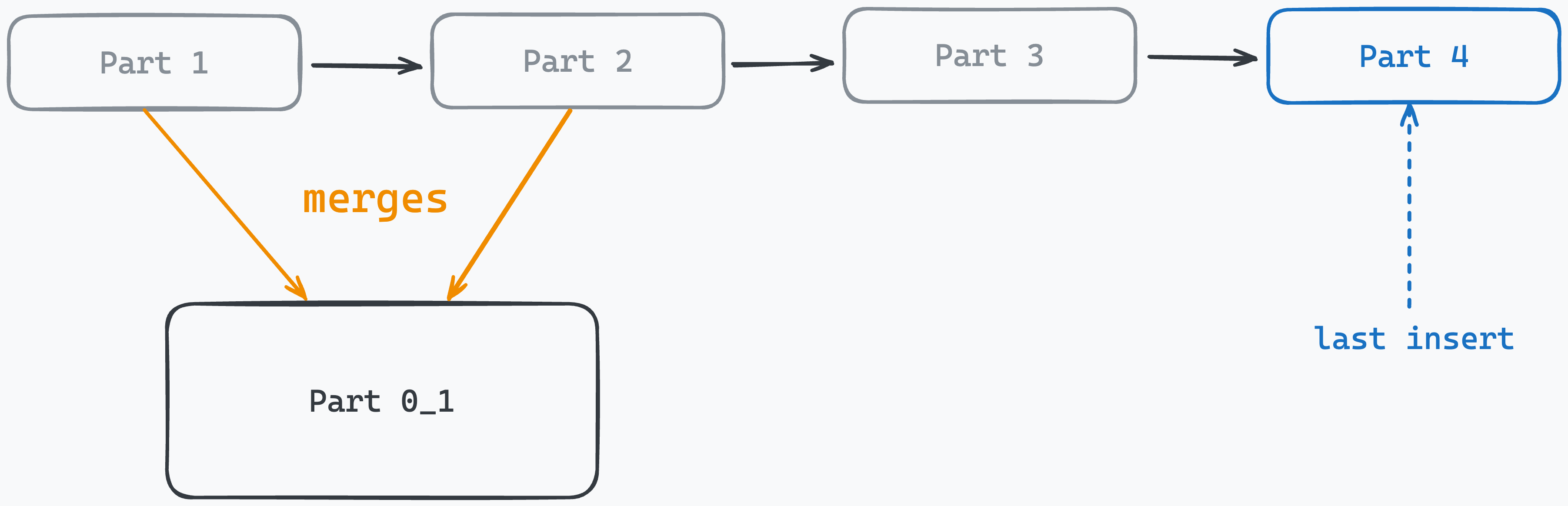
Por ejemplo Clickhouse recomienda hacer escrituras en lotes de hasta 1000, 10000 o incluso 100.000 filas. Esto es así ya que cuando clickhouse ingesta un bloque de datos, lo ordena en memoria, apliza optimizaciones y finalmente lo comprime. Cada uno de estos bloques se escribe en disco y se conoce como part y hay un proceso que se conoce como merge que se encarga de ir combinando estas partes hasta el tamaño límite (~150GB). Puedes leer más sobre esto en su blog.
Clickhouse almacena los datos por columnas en vez de por filas, y esto es una ventaja cuando quieres trabajar con grandes cantidades de datos: puedes leer únicamente las columnas que necesitas y, si optimizas los tipos de datos, podrás operar con un gran volumen de datos a la vez en memoria y tus operaciones serán muy rápidas. Puedes conseguir que tus operaciones analíticas se respondan en menos de un segundo si realizas las optimizaciones adecuadas.
Esto hace a Clickhouse una base de datos ideal para operaciones de análisis de datos, así como para obtener datos en tiempo real: analítica web (lo usa Plausible), observabilidad con OpenTelemetry o hacer análisis de datos.
ReplicatedMergeTree
El proceso que he comentado anteriormente es el funcionamiento del MergeTree en un único nodo. Cuando utilizas varios nodos, el MergeTree no genera una copia de los datos, para eso tienes el motor ReplicatedMergeTree.
Cuando configuras una tabla de tipo ReplicatedMergeTree, tienes que definir un path de zookeeper/clickhouse-keeper (lo explico en la siguiente sección) para la coordinación de los metadatos, y permitir que los nodos repliquen los datos entre sí.
Cuando creas una tabla, por defecto se creará en un único nodo del cluster. Para que se cree en varios nodos tienes dos opciones:
- Si la base de datos no es replicada, tendrás que usar la opción ON CLUSTER para que el DDL se replique en diferentes nodos.
- Si la base de datos es replicada, entonces automáticamente crea la base de datos en los diferentes nodos.
Hay otras variaciones del motor como: ReplacingMergeTree, SummingMergeTree, AgregatingMergeTree, CollapsingMergeTree, VersionedCollapsingMergeTree... que junto con las vistas materializadas, te permiten tener un pipeline de datos que, en tiempo real, te genere las agregaciones de los datos que necesites.
La teoría, aunque de primeras no es fácil, es mucho más simple que luego implementar esto en un entorno de producción donde necesitas garantizar un buen uptime y fiabilidad, pero no voy a entrar en eso en este post.
Otras integraciones (S3, MySQL, Kafka)
Hay otros tipos de motores que no voy a explicar ya que por ahora no he profundizado demasiado en ellos, pero puedes consultarlos en su [documentación](https://clickhouse.com/docs/engines/table-engines/log-family), además de contar con integraciones a todo tipo de sistemas externos: S3, MySQL, PostgreSQL o Kafka (entre otros), aunque creo que estos son los que más te interesarán ya que para trabajar con datos parecen ser lo más común.
MaterializedViews y Refreshable MaterializedViews
Esta es una de las partes más interesantes de Clickhouse. Las vistas materializadas son triggers que se ejecutan cuando insertas datos en una tabla, y te permite tener diferentes tipos de transformaciones y/o agregaciones precalculadas en tiempo real.
Recientemente han añadido las RefreshableMaterializedViews que te permiten ejecutar una consulta cada cierto tiempo, como un cron, pero sin necesidad de mantener sistemas externos. Si utilizas varios nodos, es importante que prestes atención a la documentación para definir la coordinación entre nodos y que la ejecución sea en un único nodo.
Clickhouse en producción
En mi caso trabajo con kubernetes sobre AWS o EKS. Si trabajas con kubernetes puedes desplegar un cluster con el operador de Altinity, aunque si lo prefieres puedes desplegarlo sobre EC2/on-premise, o también tienes la opción de Clickhouse Cloud, todo dependerá de tu situación.
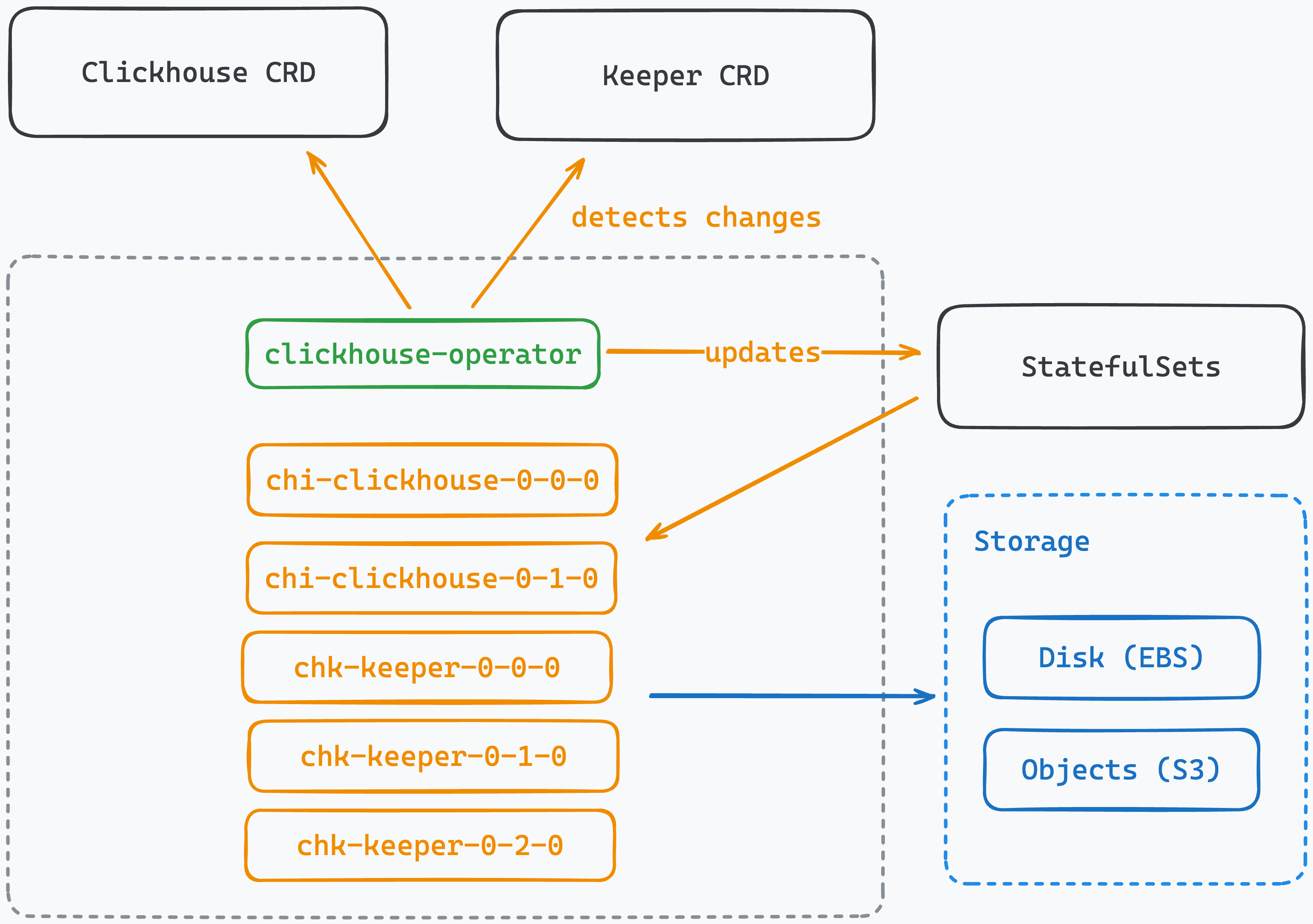
El operador de altinity simplifica muchas operaciones y lo recomiendo, aunque ciertos mantenimientos pueden ser todo un reto. Este operador te permite configurar varios clusters con diferentes topologías (replicas/shards):
- Replicas: contienen una copia completa de los datos. Tanto si utilizas uno o varios shards, lo recomendable es tener al menos una réplica por redundancia y fiabilidad.
- Shards: cuando tus datos no caben en una máquina, o quieres dividirlos por optimizar el ancho de banda. Añade una capa de complejidad extra, ya que tienes que definir un partition key y utilizar una tabla distribuida sobre tus ReplicatedMergeTree.
Si te preguntas por qué configuración elegir, dependerá del volumen de datos que tengas. En mi caso he optado por una configuración más simple de 1 shard y 2 ó 3 réplicas, aunque siempre se puede evolucionar hacia otra topología.
Coordinación con Zookeeper/Clickhouse-Keeper
En el momento en el que quieras tener más de un nodo, que es lo mas normal en cualquier entorno de trabajo, tendrás que desplegar un cluster de Zookeeper o de Clickhouse Keeper para la coordinación de metadatos entre los nodos.
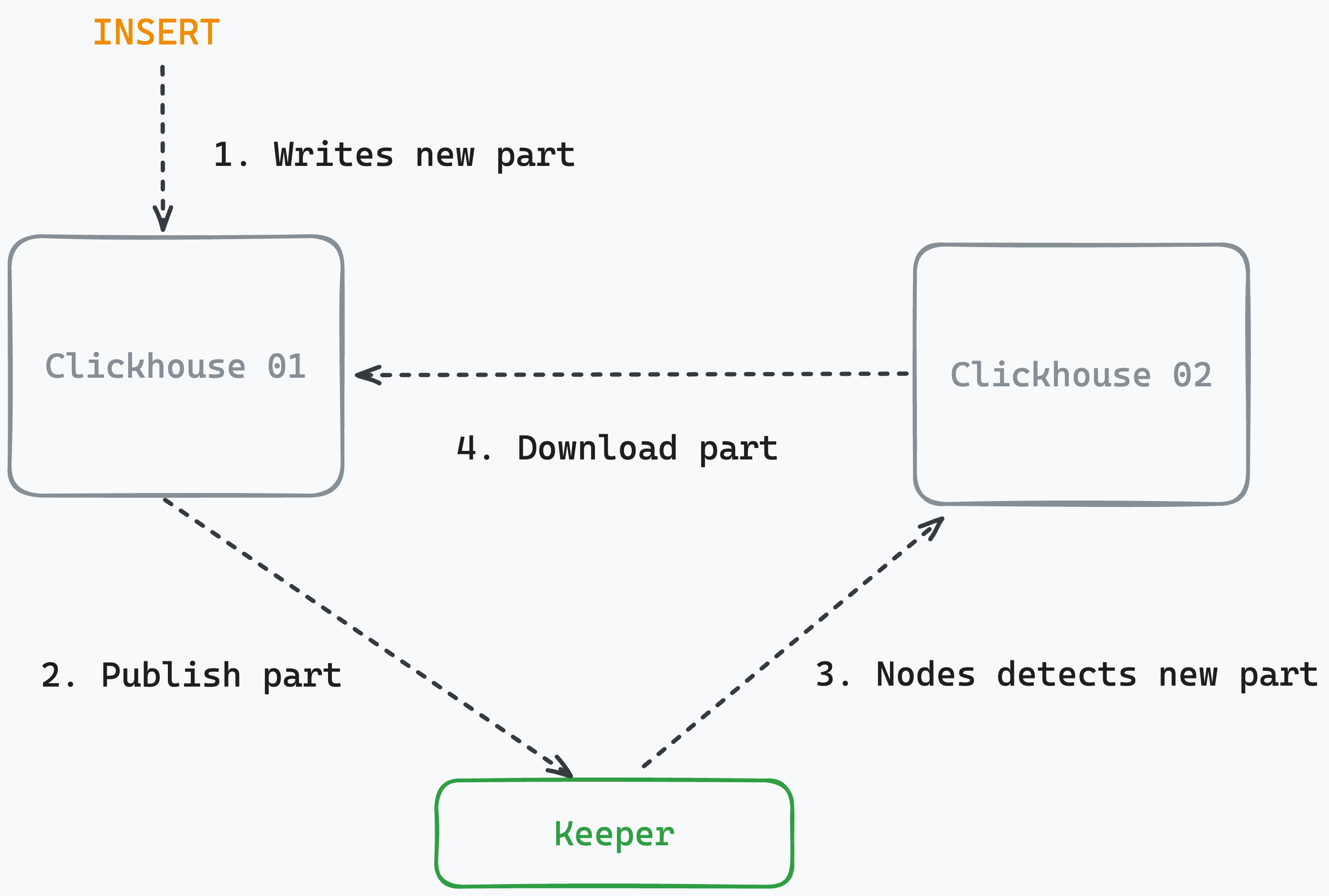
Estos últimos meses hemos tenido el cluster con Zookeeper y ha sido muy estable, aunque la recomendación es utilizar clickhouse-keeper. Lo migramos esta semana y por ahora, hemos encontrado un problema con la coordinación en un caso concreto, aunque creo que ya ha sido resuelto en una nueva release y es un caso esquina.
El operador de altinity tiene un CRD que puedes utilizar para desplegar keeper.
Almacenamiento
Esta es la parte más interesante, ya que clickhouse hace un uso intensivo de disco pero, a su vez, es muy flexible y te permite una configuración por niveles para tener varias capas de storage. Destacar que clickhouse tiene integración nativa con S3, por lo que es muy fácil realizar operaciones de lectura y de escritura a S3 para tener un patrón hot/cold, tener tus backups o ingestar nuevos datos de S3 directamente.
Aquí las opciones, si están en cloud, es utilizar discos EBS con una buena reserva de IOPS y de Bandwidth, o incluso utilizar el patrón JBOD (Just a Bunch Of Disks) de forma que se paralelizan las escrituras y las lecturas entre varios discos. Es importante que estos discos estén redundados, aunque si estás en cloud no necesitas preocuparte tanto pero sí que te recomiendo que generes backups.
Otra configuración es tener los datos que entran en un disco NVME local y moverlos a EBS o S3. También puedes separar el cómputo del storage, de forma que puedas autoescalar los nodos del almacenamiento como hacen en su cloud con el Engine SharedMergeTree. Aunque este Engine no está disponible en la versión open source, en su defecto los engine de la familia MergeTree tienen soporte para escribir en S3, pero hay una discusión abierta ya que por defecto cada nodo escribe los parts en S3 y el modo zero-copy, que permite tener una única copia de los datos, parece tener algunso problemas (discusión en GitHub).
Esta parte me resulta la más interesante y aún no tengo una respuesta clara de qué es lo mejor, así que por lo pronto la opción de utilizar EBS con nodos fijos es lo más simple para gestionarlo, mientras profundizo en cómo se podría mejorar.
Siguientes pasos: Observabilidad
Una vez entiendes los conceptos base y montas un cluster en producción, te enfrentarás a todo tipo de retos y problemas que tendrás que ir aprendiendo y solucionando: tendrás que conocer las tablas del sistema, cómo configurar los diferentes settings,
La verdad es que Clickhouse es una obra de ingeniería y personalmente me encanta lo bien que está diseñado, llevo estos últimos meses estudiando y aprendiendo cómo funciona internamente y es una pasada. Siempre me ha gustado programar con C/C++ y sería un gran reto realizarles alguna contribución a su codebase.
Por otro lado si lo despliegas te recomiendo que tengas buenas herramientas de observabilidad para poder entender qué ocurre y cómo funciona. Esta parte la exploraré en otro post en el futuro ya que es algo en lo que aún estoy trabajando.